From Alerts to Autonomy: A Practical Guide to Autonomous IT for Modern Ops Teams
IT operations has reached an inflection point. The scale, speed, and interdependence of modern digital systems have outgrown the limits of human-centric operations. While AI has been widely introduced into IT tools over the past few years, much of that adoption has focused on incremental improvements—better alerts, faster analysis, smarter dashboards.
Autonomous IT represents a more fundamental shift.
It is not about adding AI features to existing workflows, but about redesigning how IT systems are operated—moving from human-driven control to systems that can observe, decide, and act on their own, within defined guardrails.
This article provides:
- A comprehensive, technical definition of Autonomous IT
- A maturity model describing levels of autonomy
- Why now is the right time to seriously consider Autonomous IT
- How LogicMonitor enables Autonomous IT in practice
What Is Autonomous IT?
Autonomous IT is an operational model in which IT systems continuously monitor themselves, understand context and impact, make decisions, and execute actions with minimal human intervention—while operating within explicit policies and constraints defined by humans.
Autonomous IT systems exhibit several core capabilities:
1. Continuous Sensing
Autonomous systems ingest telemetry across domains:
- Infrastructure (compute, storage, network)
- Cloud and container platforms
- Applications and services
- Logs and events
- User and digital experience signals
- Third-party and internet dependencies
Continuous sensing in Autonomous IT goes beyond traditional monitoring by treating telemetry as a living, real-time representation of system behavior rather than a collection of static signals.
It requires ingesting high-fidelity data across infrastructure, applications, networks, and external dependencies, while preserving temporal accuracy and context.
Just as important, sensing must include service-level and user-experience signals, not only component health, so the system can detect degradation before outright failure.
Without this breadth and continuity of data, autonomous systems are effectively operating blind, unable to differentiate between localized noise and systemic risk. The system must continuously sense both technical state and service impact.
2. Contextual Understanding
Contextual understanding is what allows an Autonomous IT system to reason about what it observes. This capability depends on continuously maintained service topology, dependency relationships, change awareness, and historical behavior patterns.
Context transforms raw telemetry into meaning—for example, identifying whether an anomaly affects a non-critical background process or a revenue-generating service during peak traffic. This understanding is dynamic rather than static, adapting as environments scale, services evolve, and dependencies shift, and it is essential for preventing incorrect or unsafe automated actions.
Autonomous IT systems understand:
- Service topology and dependencies
- Business context (critical services, SLAs, SLOs)
- Change context (deployments, config changes)
- Historical behavior and normal baselines
This enables the system to distinguish between: “A server metric exceeded a threshold”
And “A customer-facing service is degrading and is likely to violate its SLO.”
3. Decision-Making
Autonomy requires decision-making, not just prediction. Decision-making is the most misunderstood capability of Autonomous IT, often confused with prediction or recommendation.
In reality, autonomous decision-making involves selecting an appropriate response—or deciding to take no action—based on confidence, policy, and risk. This requires explicit logic around blast radius, failure modes, and business impact, as well as the ability to degrade gracefully when certainty is low. Effective decision-making systems know when to act immediately, when to gather more information, and when to escalate to humans, making them fundamentally different from tools that simply surface insights.An Autonomous IT system can determine:
- Whether an observed condition matters
- What the likely root cause is
- What action (if any) is appropriate
- How risky that action is
- Whether to act automatically or escalate
This requires confidence scoring, policy enforcement, and blast-radius awareness.
4. Action and Execution
Action and execution turn autonomy from analysis into operational reality. This capability requires reliable, repeatable automation that is tightly integrated with monitoring and decision logic, forming closed control loops rather than one-off scripts.
Autonomous IT systems can execute actions such as:
- Triggering remediation workflows
- Adjusting configurations or routing
- Scaling resources
- Rolling back changes
- Suppressing or escalating incidents
Actions must be observable, auditable, and reversible, with built-in validation to confirm whether the intended outcome was achieved. Importantly, autonomous execution does not mean acting aggressively; well-designed systems apply proportional responses, resolving issues quietly when possible and escalating only when automation cannot safely proceed.
5. Learning Over Time
Learning over time allows Autonomous IT systems to improve their effectiveness without increasing risk. Rather than relying solely on retrained models, learning is driven by outcomes: whether actions resolved incidents, reduced impact, or introduced unintended side effects.
This feedback loop enables systems to refine confidence thresholds, expand the scope of safe automation, and reduce false positives. For operations teams, this learning capability is what makes autonomy sustainable, ensuring that the system becomes more reliable and trustworthy with use rather than more brittle.
Autonomous IT systems improve by learning from outcomes:
- Did the action resolve the issue?
- Did it cause unintended consequences?
- Was escalation appropriate?
Levels of Autonomous IT
A useful way to understand Autonomous IT is through a maturity model, similar to self-driving vehicles.
Level 0: Manual Operations
Still prevalent in many environments today, at Level 0, IT operations are entirely human-driven, relying on static thresholds, manual monitoring, and reactive troubleshooting. Alerts are generated without context, requiring operators to triage, correlate, and diagnose issues under time pressure. Reliability depends heavily on individual expertise and institutional knowledge, making outcomes inconsistent and difficult to scale as environments grow in complexity.
- Human monitoring
- Static thresholds
- Manual triage and remediation
- Alert fatigue is common
Level 1: AI-Assisted Operations
Level 1 introduces AI and analytics to improve visibility and reduce noise, typically through anomaly detection, smarter alerts, and basic correlation. While these capabilities can significantly reduce alert fatigue, humans remain responsible for determining impact, root cause, and remediation. AI accelerates analysis but does not change the fundamental operating model, with people still firmly in the critical path for every incident.
- Smarter alerts
- Anomaly detection
- Basic event correlation
- Human still makes all decisions
This is where many “AI-powered” tools stop.
Level 2: Context-Aware Recommendations
At Level 2, systems begin to understand operational context, including service dependencies, historical behavior, and business relevance. Events are correlated into meaningful incidents, and probable root causes are identified automatically, allowing teams to focus on what matters most. Human operators still approve actions, but their role shifts from triage to validation, enabling faster and more consistent response without sacrificing control.
- Root cause analysis
- Incident correlation
- Suggested remediation steps
- Human approval required before action
Level 2 reduces cognitive load but does not remove humans from the critical path.
Level 3: Conditional Autonomy
Level 3 marks the transition from insight to action, with systems executing predefined remediation steps when confidence and policy conditions are met. Known, low-risk issues are resolved automatically, while uncertain or high-impact scenarios are escalated to humans. This level delivers tangible operational leverage by reducing mean time to mitigation and removing repetitive toil, while preserving safety through guardrails and oversight.
- Automated actions for known, low-risk scenarios
- Guardrails and confidence thresholds
- Humans oversee and intervene when needed
This is where real operational leverage begins.
Level 4: High Autonomy
At Level 4, autonomous systems handle the majority of operational decisions and responses, with humans focusing on governance, optimization, and exception management. Incidents that require human intervention are rare and typically involve novel or high-risk situations. Operations teams evolve into designers of reliability, continuously refining policies, automation, and system resilience rather than reacting to day-to-day failures.
- Most incidents resolved without human involvement
- Humans focus on exceptions, policy, and improvement
- Continuous learning improves accuracy and scope
Level 5: Full Autonomy (Aspirational)
Level 5 represents a fully self-managing IT environment where systems operate end-to-end without human intervention, guided solely by intent, policy, and business objectives. While largely aspirational today, this level provides a long-term direction for Autonomous IT, emphasizing continuous adaptation, self-healing, and alignment with business outcomes. In practice, most organizations aim to approach this level selectively rather than universally.
- End-to-end self-healing systems
- Humans define intent, policy, and objectives
- Rare in practice today, but a long-term direction
Most organizations today operate between Levels 1 and 2. Autonomous IT is about deliberately progressing upward.
Why Now Is the Time for Autonomous IT
1. System Complexity Has Surpassed Human Scale
Modern environments include hybrid and multi-cloud architectures, microservices and ephemeral infrastructure, SaaS applications, third-party dependencies, internal and external APIs, a stack of security technologies, plus global users with real-time expectations.
No operations team—regardless of skill—can manually reason about these systems fast enough during incidents.
2. Reactive Operations Do Not Scale
Traditional workflows that look like
Alert → Triage → Correlate → Diagnose → Act
Break down when alerts arrive faster than humans can process, when root cause spans multiple domains, and when the impact is indirect or user-centric.
Autonomous IT shifts the model toward impact-first operations, where systems identify what matters most and act proportionally.
3. Reliability Is Now a Business Metric
Among other interesting findings, the 2025 SRE report found that reliability is now a key business metric. It should be no surprise given that every business runs on digital systems. IT operations is accountable not just for uptime, but for:
- Customer experience
- Revenue protection
- Brand trust
- Compliance and risk
Autonomous systems can continuously enforce service objectives and act before failures become business incidents.
4. AI Alone Is Not Enough
Many tools today use AI for:
- Alert classification
- Anomaly detection
- Chat-based interfaces
These are valuable—but insufficient. Without decision-making and execution, AI simply accelerates human overload. Autonomous IT integrates AI into closed-loop operational control, which is fundamentally different.
How LogicMonitor Enables Autonomous IT
LogicMonitor supports Autonomous IT by providing the foundational capabilities required to move beyond AI-assisted monitoring toward autonomous operations.
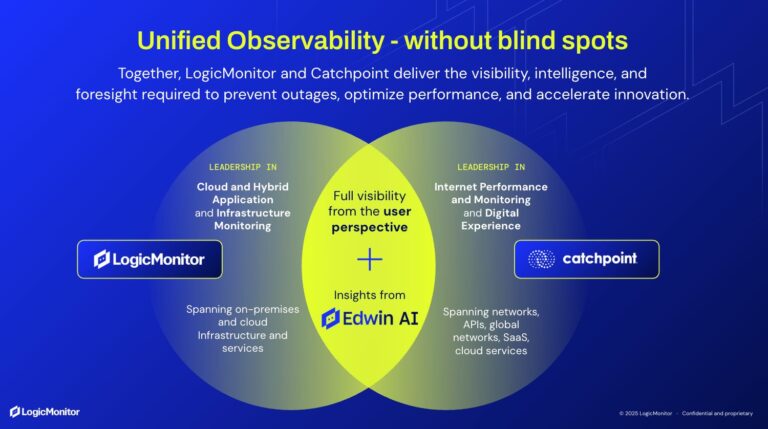
1. Unified, Continuous Observability
LogicMonitor provides deep visibility across: on-prem and cloud infrastructure, networks (internal and external) and devices, applications and services, and hybrid and dynamic environments.
This unified telemetry is essential for autonomous decision-making—autonomy fails without full context. You can’t automate what you can’t see.
2. AIOps and Intelligent Event Correlation
LogicMonitor’s AIOps capabilities (including Edwin AI) correlate alerts and events across domains into meaningful incidents.
This enables:
- Noise reduction
- Faster detection of true problems
- Identification of probable root causes
Correlation is a prerequisite for autonomy—systems must know what to act on.
3. Contextual Root Cause Analysis
By understanding dependencies and relationships, LogicMonitor can isolate causal issues rather than symptoms.
This is critical for:
- Avoiding incorrect automated actions
- Reducing blast radius
- Increasing confidence in remediation decisions
4. Dynamic Baselines and Predictive Insights
LogicMonitor uses dynamic baselines instead of static thresholds, allowing systems to recognize abnormal behavior in complex, changing environments.
This supports:
- Early detection of degradation
- Proactive intervention
- Reduced manual tuning
Prediction alone is not autonomy, but it enables earlier and safer action.
5. Automation and Closed-Loop Remediation
LogicMonitor supports event-driven automation and integration with remediation workflows.
This allows organizations to:
- Automate responses to known issues
- Implement self-healing for low-risk scenarios
- Progress from recommendations to action
When combined with confidence thresholds and policies, this enables Level 3 conditional autonomy.
6. Automated Diagnostics and Context Enrichment
LogicMonitor can automatically collect diagnostic data when issues occur, enriching incidents with the context needed for both human and automated decision-making.
This increases:
- Decision accuracy
- Trust in automation
- Speed of resolution
Autonomous IT Is a Journey, Not a Switch
Autonomous IT is not about eliminating human operators. It is about:
- Reducing toil
- Scaling operational decision-making
- Allowing humans to focus on architecture, resilience, and improvement
The organizations that succeed will not “buy autonomy.” They will build it progressively, starting with visibility, correlation, context, and controlled automation.
LogicMonitor provides the observability, intelligence, and automation foundations required to support that journey—without over-promising full autonomy before teams are ready.
Autonomous IT is not AI washing.
It is a response to a structural reality: modern IT systems now operate at machine speed, and operations must evolve accordingly.
Translating Autonomous IT into an SRE / NOC Operating Framework
Autonomous IT is not a replacement for SRE or NOC models—it is an evolution of how those teams operate as systems become too complex and fast-moving for manual control.
The key shift is this: Humans move from being real-time operators to designers, governors, and exception handlers of automated control loops.
Core Principle: Control Loops Replace Linear Workflows
Traditional ops workflows are linear:
Alert → Triage → Diagnose → Fix → Verify → Document
Autonomous IT reframes operations around continuous control loops:
Observe → Understand → Decide → Act → Validate → Learn
SRE and NOC teams evolve by owning different parts of this loop at different autonomy levels.
Autonomous IT Mapped to SRE & NOC Maturity Levels
Level 0–1: Manual / AI-Assisted Operations
(Most NOCs and many SRE teams today)
Operating Model
- NOC:
- 24×7 alert monitoring
- Ticket creation and escalation
- Manual correlation across tools
- SRE:
- Incident response
- Postmortems
- Manual SLO tracking
Tool Role
- Monitoring provides alerts and dashboards
- AI may reduce noise, but humans still:
- Decide what matters
- Perform diagnosis
- Execute remediation
Human Role
- Humans are in the critical path
- Success depends on experience and heroics
Metrics
- MTTA / MTTD
- Alert volume
- Incident counts
Level 2: Context-Aware Operations (Recommended Starting Point)
What Changes
This is where Autonomous IT begins to materially change daily work.
Operating Model
- NOC:
- Monitors incidents, not alerts
- Focuses on service impact and severity
- Fewer escalations, higher signal quality
- SRE:
- Owns service definitions, SLOs, dependencies
- Reviews AI-identified root causes
- Defines remediation runbooks
Tool Role
- Event correlation
- Probable root cause analysis
- Dynamic baselines
- Automated diagnostics
Human Role
- Humans validate decisions, not raw data
- Engineers spend less time triaging
- Knowledge becomes encoded into the system
Metrics Shift
- Alert-to-incident ratio
- Time to root cause
- SLO breach avoidance
This level is critical because it builds trust—without trust, autonomy stalls.
Level 3: Conditional Autonomy (Self-Healing Begins)
Operating Model
- NOC:
- Oversees autonomous actions
- Handles exceptions and confidence failures
- Acts as a safety net, not first responder
- SRE:
- Designs automation and guardrails
- Defines “safe-to-act” conditions
- Reviews outcomes, not every action
Control Loops in Practice
Examples:
- Restart a failed service instance
- Roll back a bad deployment
- Reroute traffic away from degraded dependencies
- Suppress symptom alerts automatically
All actions are:
- Confidence-scored
- Policy-bound
- Fully observable and auditable
Human Role
- Humans define:
- When automation is allowed
- Blast-radius constraints
- Escalation thresholds
- Humans intervene only when automation is uncertain
Metrics
- % of incidents auto-resolved
- Mean time to mitigation (MTTM)
- Automation success vs rollback rate
Level 4: High Autonomy Operations (SRE as System Designers)
Operating Model
- NOC:
- Shrinks or transforms into an exception-management team
- Focuses on anomaly review and governance
- SRE:
- Owns system reliability as a product
- Continuously improves control loops
- Optimizes resilience and cost
Day-to-Day Work Looks Like:
- Reviewing automation performance
- Adjusting confidence thresholds
- Expanding autonomous coverage
- Designing failure-tolerant architectures
Incidents that reach humans are:
- Novel
- High risk
- Multi-domain
- Business-critical
Metrics
- SLO compliance
- Error budget burn rate
- Incident recurrence
- Customer-impact minutes
LogicMonitor supports this evolution by acting as the control-plane foundation:
- Observe: Unified telemetry across infrastructure, cloud, network, and services
- Understand: AIOps correlation, dependency-aware root cause analysis
- Decide: Dynamic baselines, confidence scoring, contextual insight
- Act: Event-driven automation and remediation workflows
- Validate: Continuous monitoring of post-action outcomes
This allows SRE and NOC teams to incrementally increase autonomy without destabilizing operations.
Key Takeaway for Leaders
Autonomous IT is not a reorg—it is an operating model shift.
The winning organizations will:
- Start with context and trust
- Encode expertise into systems
- Move humans out of the critical path gradually
- Measure success by outcomes, not activity
SRE and NOC teams do not disappear in Autonomous IT.
They become the architects of reliability at machine speed.