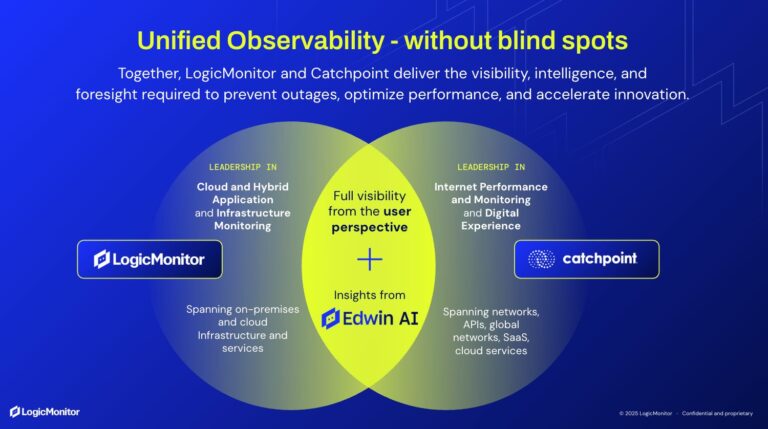
Each year, the SRE Report examines how reliability evolves in real-world practice. The 2026 edition continues that tradition but with a clear shift in focus. The industry conversation has moved beyond uptime goals, tooling disputes, and narrow operational metrics.
After eight years of data, one trend stands out: reliability has outgrown its engineering confines and now shapes how organizations operate and make decisions.
The central question behind this year’s findings is simple:
Are organizations treating reliability as an operational function—or as a fundamental business capability?
While many teams believe they’ve made that leap, the data suggests execution still trails intent. The following sections summarize the findings with the most significant operational impact.
1. Performance Degradation Is Seen as Risk, but Rarely Quantified
The concept that “slow is the new down” is now broadly accepted. Around two-thirds of respondents, including managers, agree that degraded performance is just as serious as an outage. That alignment is important, especially as reliability discussions expand beyond engineering.
Yet conviction has outpaced execution:
- Roughly one-third of organizations still separate performance and uptime concerns.
- Only 26% consistently measure whether performance improvements influence business outcomes like NPS or revenue.
- Fewer than one in four model the financial cost of downtime or severe degradation.
The result is a recurring mismatch: teams know performance matters but often lack business-language evidence to support prioritization.
From an operational leadership standpoint, this remains one of the widest reliability gaps. If latency isn’t quantified as a risk, it can’t be effectively prioritized, defended, or funded. Moreover, customers don’t live inside your cloud or datacenter—they live everywhere. If monitoring doesn’t reflect where real experience happens, your reliability picture is incomplete.
2. Reliability Metrics Rarely Reach Business Decision-Making
The report also shows how reliability is formally measured.
Only 21% of organizations track reliability as a business KPI, with most metrics still siloed inside engineering or operations dashboards.
This isn’t a tooling issue—it’s an organizational decision. The outcomes are predictable: when reliability lives only within technical teams, it becomes easier to defer, harder to weigh against growth goals, and more likely to stay reactive.
Once reliability enters business planning cycles, its value changes. It becomes measurable alongside strategic priorities and easier to justify as an investment.
Here, Internet Performance Monitoring plays a complementary role. By connecting external dependencies—like networks, CDNs, DNS, and cloud edges—to customer experience, reliability conversations evolve from system availability to service trustworthiness.
3. AI Is Shifting Effort, but Benefits Remain Uneven
AI continues to reshape reliability operations, though its influence is often overstated.
- Median toil now stands at 34%, slightly higher than last year.
- 49% of respondents report reduced toil due to AI.
- 35% report no real change.
- A smaller portion say toil has increased.
A key pattern is the perception gap between leaders and practitioners. Directors are far more likely to see reduced toil than individual contributors. Leaders view AI’s scaling efficiencies, while practitioners confront new friction around configuration, validation, and exception handling.
AI’s consistent value doesn’t lie in removing complexity, but in managing it better—through faster signal correlation, assisted triage, and reduced manual integration work.
In short, AI is changing how effort is applied, not eliminating the need for expertise.
4. Resilience Testing Still Limited by Organizational Risk Tolerance
Although most organizations recognize resilience as critical, few regularly test it in production.
- Only 17% conduct chaos experiments in production environments.
- About one-third have never tested failure in production.
- Fewer than 40% practice chaos engineering and receive full organizational backing.
The data reveals two interlinked patterns. Teams that test failure gain confidence and respond faster during incidents. Those that avoid testing remain constrained by risk aversion, leading to slower recovery and increased uncertainty.
This matters because resilience work often targets systems and infrastructure—but without visibility into digital experience, teams can’t assess who is affected, where issues occur, or how severity differs by region or market.
The barrier isn’t tooling; it’s leadership mindset. Many now refer to this work as “resilience engineering” rather than “chaos engineering”—not as a rebrand, but as a reframing that aligns expectations and lowers perceived risk.
5. Architecture Matters Less Than Data Coherence
The long-running debate between best-of-breed tools and integrated platforms persists, but it no longer drives reliability outcomes.
- Preferences between platforms and best-of-breed remain evenly split.
- 55% of organizations still spend significant time on tool integration.
- Even platform-leaning teams report notable integration overhead.
The data suggests architecture alone doesn’t define maturity. Shared data models, governance, and contextual consistency matter more. Without them, reliability work fragments instead of compounding.
AI reinforces this principle. When data is consistent and high-quality, AI can correlate events and automate action. When it’s fragmented, AI effort shifts to reconciliation rather than insight.
6. Limited Learning Time Becomes a Structural Risk
A quietly critical finding emerges later in the report:
- Most engineers dedicate only 3–4 hours per month to learning.
- Just 6% have protected learning time.
- Lack of growth opportunity is a top driver of attrition.
This isn’t merely a people issue—it’s operational.
As systems grow more distributed and AI-driven, skills decay and knowledge gaps increase operational risk. Organizations that fail to safeguard learning time are often trading long-term reliability for short-term output.
The report concludes clearly: the next leap in reliability will not come from more tools. It will come from leaders protecting time for learning, experimentation, and reflection.
Meanwhile, engineers lack the bandwidth to manually process every signal, incident, or performance anomaly. The need is for observability tools that do more than alert—tools that reduce cognitive load, explain behavior, and enable faster, more confident action.
Reliability Has Become a Leadership Imperative
The 2026 SRE Report doesn’t spotlight a single technology trend. It highlights a shift in how reliability is conceived and led.
Reliability today is:
- Experienced as performance and responsiveness, not just availability.
- Justified through business outcomes, not technical metrics alone.
- Influenced by AI, yet limited by culture and structure.
- Defined as much by time, trust, and learning as by technology.
For IT and operations leaders, the message is clear: reliability is no longer about what’s monitored—it’s about how effectively it’s aligned, communicated, and sustained.
For a full view and deeper analysis, read the 2026 SRE Report.